

In early 2024, a large global technology services company found itself in the middle of an uncomfortable moment. The organisation had done everything it believed was right. Over the previous eighteen months, it had invested heavily in cloud upskilling programs, rolled out new internal learning platforms, partnered with reputed training providers, and proudly reported completion numbers to leadership every quarter. The teams weren’t untrained. They had spent months preparing. But when the project finally went live, the team slowed down in ways no one had planned for, not because they didn’t care, but because they weren’t sure how to move next.
What failed was not the technology. What failed was not the intent. What failed was something harder to see. The team assigned to the project hesitated at key moments. Senior engineers were pulled in repeatedly to unblock basic issues. Decisions that should have taken minutes stretched into hours. The work eventually got done, but not without stress, cost overruns, and a quiet loss of confidence.
In the post-mortem that followed, one question kept surfacing in different forms: how did people who looked fully trained struggle so much when it mattered?
This was not an isolated incident. Across industries, Across the enterprise world, similar conversations were unfolding quietly. People were learning. People were passing assessments. But readiness, the ability to perform under real conditions, was uneven and unpredictable. And no existing metric seemed capable of explaining why.
This is the uncomfortable space, the “gap” where EASE, the Engine for AI-based Skill Evaluation, comes into the picture. Not as a shiny new assessment tool, but as a response to a long-standing blind spot in how enterprises understand capability.
When Learning Looked Successful but Delivery Told a Different Story
For years, enterprise skilling followed a familiar rhythm. Employees enrolled in programs. They watched videos, completed modules, took tests, and earned scores. Learning teams tracked participation and progress. Leaders reviewed reports that showed steady movement forward. The assumption, rarely stated out loud but deeply embedded, was simple: learning would translate into performance.
Most of the time, no one questioned that assumption. As long as projects moved forward and clients stayed satisfied, the system appeared to work. But as technology stacks became more complex, delivery timelines tighter, and AI-driven systems entered everyday workflows, the cost of that assumption began to rise.
When things went wrong, the gap became visible. Not as a dramatic collapse, but as friction. Slower execution. Increased dependence on a few senior individuals. Teams that needed more handholding than expected. Managers who hesitated before staffing projects, not because talent was unavailable, but because confidence was missing.
What enterprises slowly realised was this: they had become very good at measuring learning activity, but very poor at validating readiness.
The Hidden Cost of Measuring the Wrong Thing
Traditional assessments played a central role in this problem. They were designed for scale and convenience. Questions had right answers. Scoring was fast. Results were easy to compare. But these assessments measured familiarity far more than capability. They rewarded recall, pattern recognition, and speed within controlled environments.
Real work does not arrive in controlled environments. It arrives with incomplete information, broken dependencies, conflicting priorities, and systems that behave unpredictably. It requires sequencing, judgement, and recovery when things do not go as planned. None of that is visible in a multiple-choice score.
This mismatch became more obvious as roles evolved. A cloud engineer today does not just provision infrastructure. They design for resilience, cost, and security. A data engineer is not just moving data, but ensuring reliability, governance, and performance under scale. A full-stack developer is not just writing code, but integrating services, debugging failures, and responding to changing requirements. And yet, many assessments continued to treat these roles as static collections of concepts rather than living responsibilities.
Enterprises began asking harder questions.
How do we know who is actually ready to take ownership?
How do we distinguish between someone who has seen a concept and someone who can apply it under pressure?
How do we reduce risk before deployment, not after failure?
Why Finishing a Course Never Meant Being Ready
At Nuvepro, this pattern surfaced repeatedly in conversations with enterprise leaders. Teams had done everything asked of them. Courses completed, Assessments passed. Yet when it was time to assign ownership of real systems, hesitation crept in.
Passing an assessment is not the same as being ready to perform.
Real projects rarely offer clear instructions or single correct answers. They involve tradeoffs, unexpected failures, and constraints that force difficult decisions. Readiness lives in how people respond to those moments, not in how well they recall information.
This realisation changed how assessment itself was understood. Validation could no longer be treated as a checkpoint at the end of learning. It had to become proof that learning could stand up under real conditions.
This is where the idea behind EASE, the Engine for AI-based Skill Evaluation started to take shape.
EASE was not built to make assessments more difficult. It was built to make readiness visible. The insight was simple but powerful: if real work is complex, messy, and contextual, then evaluation must observe people doing real work, not answering questions about it.
What Real Work Actually Looks Like
Instead of treating assessments as checkpoints, EASE (Engine for AI-based Skill Evaluation) enables them to function as proof points. Learners are placed in environments that resemble real project conditions. They are asked to execute tasks end to end. They encounter failures, dependencies, and decisions that mirror actual workflows. What matters is not just whether they reach an outcome, but how they get there.
This shift changes the entire nature of evaluation. There is no single correct path. Two people might solve the same problem differently. One might demonstrate clarity and control. Another might stumble, recover, and still succeed. Both stories matter, and both carry different signals about readiness.
Evaluating this kind of work is not easy. Manual review struggles at scale. Different evaluators focus on different aspects. Bias creeps in. Speed becomes a bottleneck. And most importantly, final outputs alone do not tell the full story.
EASE: Making Readiness Visible
EASE addresses this by quietly observing execution as it unfolds. It looks at actions taken, sequences followed, errors encountered, and recoveries attempted. It builds a picture of how skills are applied, not just whether tasks are completed. This allows evaluation to move beyond surface-level correctness and into practical competence.
The role of AI here is not to replace human judgement, but to make consistent judgement possible at scale. By applying the same evaluation logic across learners, teams, and cohorts, EASE (Engine for AI-based Skill Evaluation) reduces subjectivity and brings clarity where ambiguity previously ruled. A readiness score begins to mean the same thing across contexts, not just within a single batch or reviewer.
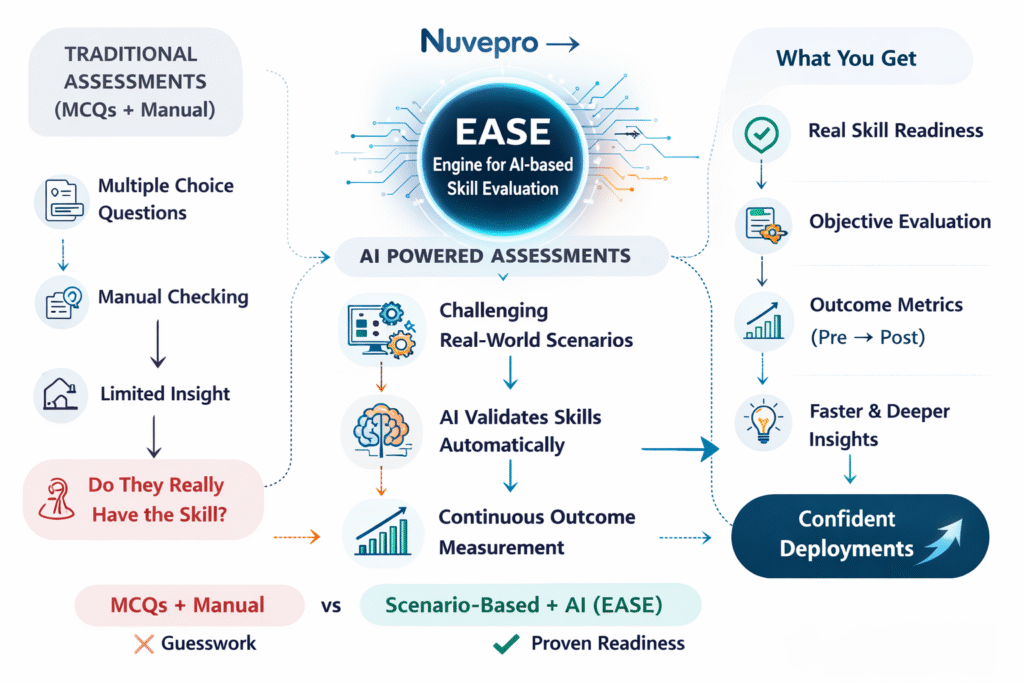
Turning Performance into Trustworthy Signals
One of the most important outcomes of this approach is trust. Learning leaders can trust the data because it reflects behaviour, not just participation. Managers can trust deployment decisions because they are based on observed capability. And learners themselves gain clearer feedback on where they stand and what they need to improve.
To make this clarity usable, EASE translates complex evaluation into simple readiness signals. Each assessment is evaluated on a structured scale, normalised to allow comparison, and mapped to readiness levels that reflect real-world expectations. These are not cosmetic grades. They indicate whether someone can operate independently, needs light guidance, or requires further support before taking on responsibility.
For enterprises, this changes how skilling decisions are made. Instead of relying on course completion rates, leaders can see who is ready to be staffed on projects. Instead of guessing where gaps exist, teams can identify them precisely. Instead of reacting to failures, organisations can prevent them.
This shift also changes the learner experience. When assessments resemble real work, preparation becomes more meaningful. Learners focus less on memorising answers and more on understanding workflows. Feedback feels relevant because it reflects actual performance. Confidence, when it comes, is earned through doing, not assumed through scores.
EASE: Easing the Gap Between Learning and Doing
As we move further into 2026, this distinction is becoming critical. AI-assisted tools, automated systems, and rapidly changing stacks mean that knowing a tool is no longer enough. What matters is the ability to apply skills responsibly, adapt quickly, and recover gracefully when systems behave unexpectedly. Readiness is no longer a nice-to-have. It is a delivery requirement.
EASE, the Engine for AI-based Skill Evaluation sits quietly at the centre of this shift. It does not demand attention. It does not promise miracles. It does one thing well: it helps enterprises see what was previously invisible.
By grounding skill evaluation in real environments and observable performance, EASE allows organisations to move from assumption to evidence. Learning stops being a hopeful investment and becomes a verifiable capability. Decisions about deployment, staffing, and upskilling are no longer based on intuition alone, but on demonstrated readiness.
This is not about abandoning learning programs or certifications. It is about completing the loop. Learning creates potential. Validation confirms capability. Without that confirmation, enterprises operate on faith. With it, they operate with confidence.
The enterprises that are adapting fastest today are not the ones training the most. They are the ones validating what training actually produces. They understand that readiness cannot be inferred. It must be observed, measured, and trusted.
That is the quiet promise of EASE. Not louder dashboards. Not more tests. But a clearer understanding of who is ready, when it matters most.
And in a world where the cost of uncertainty keeps rising, that clarity may be one of the most valuable capabilities an enterprise can build.
How Nuvepro Enables EASE - Without Disrupting How Enterprises Already Work
EASE doesn’t sit on top of learning as another layer to manage. It’s built into how Nuvepro designs and delivers skill validation from the ground up.
Nuvepro enables EASE by anchoring assessments in real environments, not simulated ones. Learners don’t just answer questions – they provision resources, configure systems, integrate tools, debug failures, and complete workflows the way they would on an actual project. This creates the raw signals EASE needs to understand how skills are applied, not just whether concepts are known.
Every action taken during these assessments is quietly observed and evaluated by EASE. Not to judge speed or surface correctness, but to understand execution quality how decisions are made, how errors are handled, and how recovery happens when things don’t go as planned.
Because EASE is embedded into Nuvepro’s project-based and role-based assessments, enterprises don’t need to redesign their learning programs to use it. Whether teams are onboarding fresh hires, reskilling experienced professionals, or preparing talent for deployment, EASE works in the background normalizing performance, reducing subjectivity, and translating real work into clear readiness signals.
The result is not more data, but better decisions.
Nuvepro doesn’t ask enterprises to train more. It helps them trust what training produces.
And that’s where EASE delivers its real value – as the engine that finally connects learning to readiness, and readiness to real-world performance.